Environnement et outils de traitement des données
L’outil logiciel préconisé est R qui permet le traitement avancé des données numériques et leur analyse statistique. Outre qu’il implémente l’état de l’art des méthodes statistiques, R offre la possibilité de tracer les données et de produire des figures de qualité. La mise en oeuvre de ces fonctionnalités est délicate à partir de l’éditeur natif de R. Pour cela différents environnements intégrés de développement encore appelés IDE (Interactive Development Environment) ont été développés afin d’améliorer la prise en main, l’efficacité et les échanges. Parmi les IDE utilisés avec R nous pouvons vous en conseiller deux :
- RStudio qui est un IDE spécifique à R et qui offre une version open-source pour Windows assez facilement installable;
- Jupyter un IDE ‘universel’ s’appuyant sur le concept de notebook qui facilite la publication, les échanges et la réutilisation du code. L’installation sous Windows n’est pas directe et nécessite d’installer la plate-forme Anaconda;
Installation de R + RStudio ou R + Jupyter via Anaconda
R + RStudio
Pour Windows :
- récupérer les exécutables (i.e. .exe) de R et RStudio via les liens ci-dessus;
- installer R en utilisant les options proposées par défaut;
- installer RStudio en double cliquant sur l’exécutable et suivre les étapes.
Anaconda
L’installation est quasi identique pour windows, linux et macOS. Nous présentons ci-dessous les principales étapes de la récupération à l’installation. Nous montrons comment créer un nouvel environnement avec R et Jupyterlab.
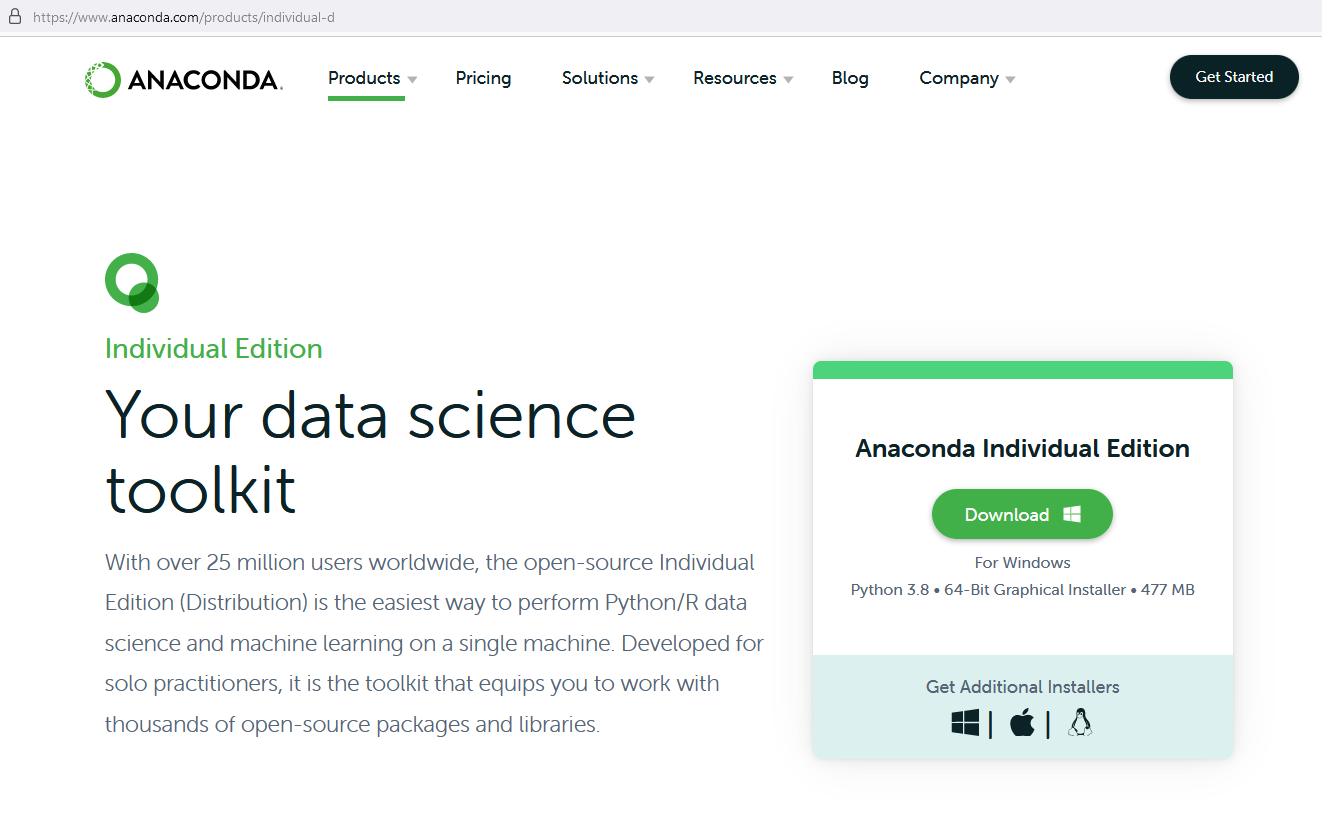
Une fois le fichier exécutable (‘Anaconda3-2022.05-Windows-x86_64.exe’) cliquer deux fois dessus pour lancer l’installation
- Anaconda Navigator -> menu démarrer
Anaconda apparaît après l’installation dans votre menu démarrer. Il faut lancer Anaconda Navigator pour gérer les environnements et l’installation des packages.
Anaconda propose un environnement isolé afin de gérer les dépendances et la version des logiciels. C’est pour cela qu’il nécessite à minima 3Go d’espace disque et un minimum de mémoire RAM.
- Anaconda Navigator -> Interface
L’interface anaconda de base propose par défaut une séries de logiciel installés ou à installer en fonction des besoins.
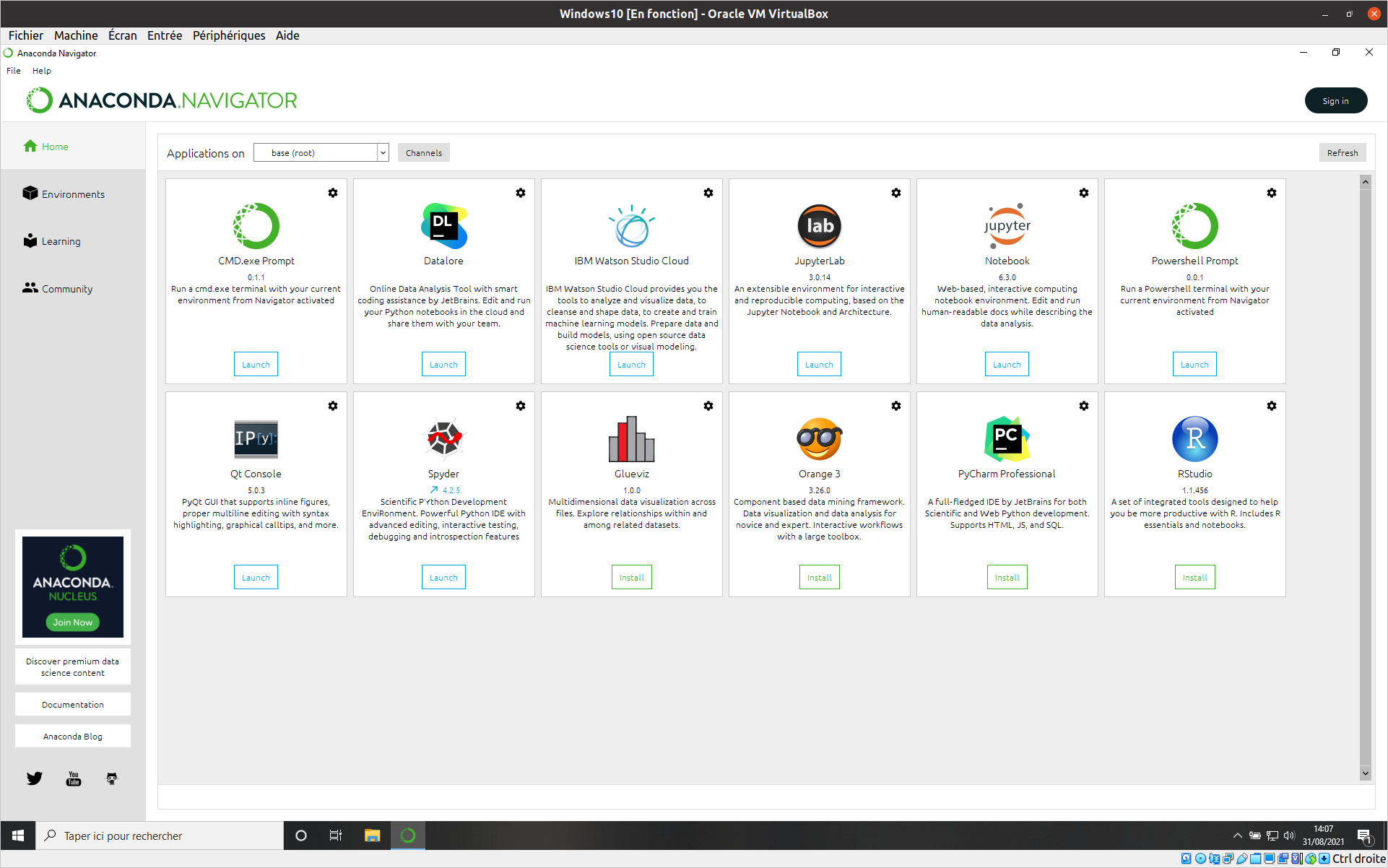
Cet environnement de base est très stable. En contrepartie ce ne sont pas les versions les plus récentes des logiciels qui sont proposées. Pour avoir des versions plus récentes il faudra ajouter un liens (Channels).
- Anaconda Navigator -> Channels
On vous propose d’ajouter le Channel ou lien conda-forge qui pointe sur les versions plus récentes et propose plus de packages.
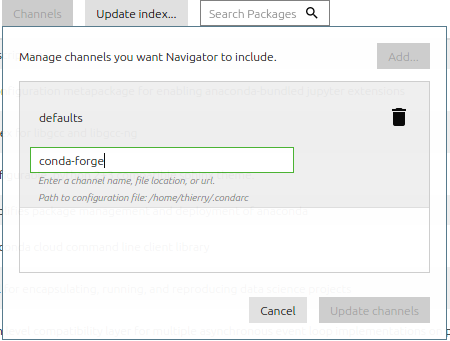
Ce Channel maintenu par une large communauté issue du monde open-source permet de créer de nouveaux environnements opérationnels pour vos besoins. Dans notre cas on vous propose une fois le Channel ajouté de créer un nouvel environnement avec une version plus récente de R, Jupyterlab et le noyau (kernel) de R pour jupyterlab.
- Anaconda Navigator -> Création d’un nouvel environnement
Ici on active l’installation de R et python. Anaconda va se baser sur le Channel conda-forge pour les versions des logiciels.
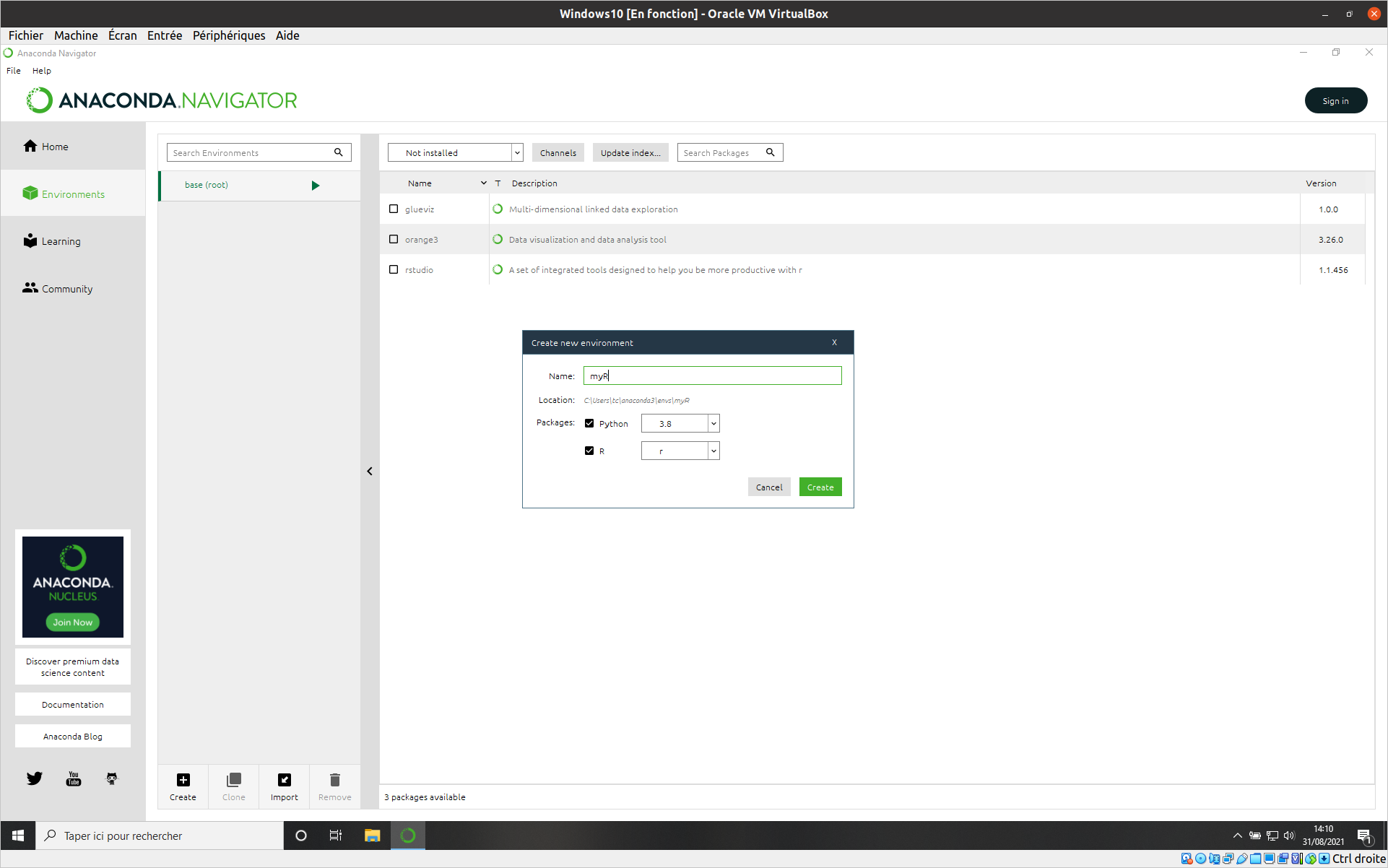
Après sa création on va pouvoir ajouter les logiciels et packages dont on a besoin et notamment jupyterlab et les libraries spécifiques en plus des librairies de base.
- Anaconda Navigator -> Installation de logiciel et librairies
Sélectionner votre nouvel environnement recherche dans les logiciels et librairies non installés jupyterlab et les libraries R listées plus bas dans la page.
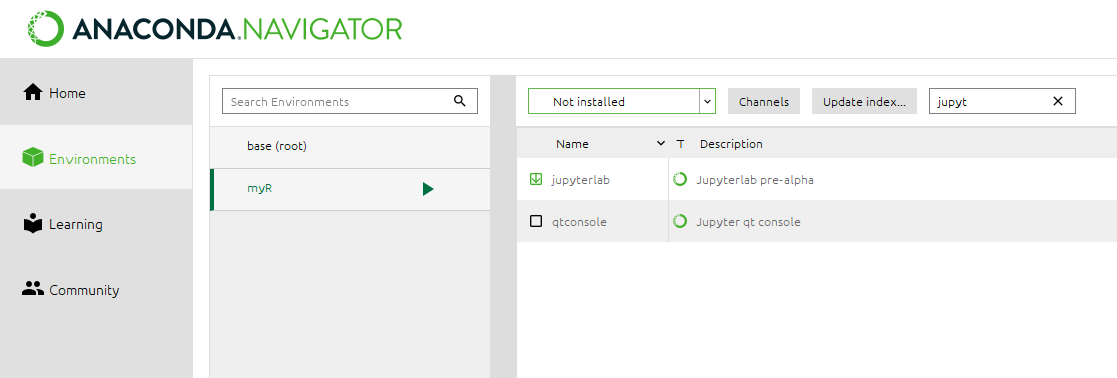
Après cette opération vous pouvez retourner sous Home et à partir de votre nouvel environnement vous pouvez lancer Jupyterlab. Jupyterlab vous permet d’ouvrir le notebook et lancer les blocs de code. Pour cela il vous faudra récupérer les données via le lien ci dessous et modifier dans le notebook le chemin d’accès aux données .
Les librairies à installer pour la séance sont :
- sf, tidyverse, dplyr, rstatix, KableExtra , rgdal, RColorBrewer, ggplot2
Script et données
Spatial
Les données, les scripts et les docs sont à récupérer ici : data. Attention ce lien est temporaire !
Temporel
Installer la librairie xts
Les données + script + doc pour la manipulation et l’analyse de séries temporelles sont ici : data.
Nous reviendrons au cours de la séance sur les différentes étapes.
Analyse données géographiques : Interpolation spatiale
Objectifs :
Afin de pouvoir estimer la part de contribution du ruissellement des pluies sur la pollution au phosphore, il est nécessaire de connaître le cumul de précipitations en tout point du bassin versant. Malheureusement, cette information n’est pas mesurée au niveau du bassin de la Sorme. Les stations climatiques disponibles sont situées à l’extérieur de ce dernier.
Pour estimer les cumuls de pluie au niveau de bassin versant, nous vous proposons de mobiliser des méthodes d’interpolation spatiale.
L’objet de cette dernière partie de l’UE 2 : traitement de la donnée est de vous faire mobiliser des méthodes et outils standards d’interpolation spatiale des données :
* La régression multiple
* Le krigeage ordinaire (technique appartenant à la discipline des géostatistiques)
Vous serez guidés pas à pas pour interpoler les cumuls annuels de pluie mesurés par le réseau des stations de Météo-France.
Le support du TP, les données (MNT, départements, BV), les scripts pour les 3 premières étapes sont à récupérer (ici)
Les étapes du travail
- Lecture des données ;
- Agrégation des données climatiques au pas de temps annuel par station et pour toute la période;
- Nettoyage et sélection des données pour l’interpolation;
Étape 2 : Exploration et modèle de régression
- Construction du modèle linéaire multiple entre variables explicatives (X, Y et altitude) et la variable climatique (corrélations);
- Mesure de la significative des variables retenues dans le modèle (r, p-value);
- Évaluation de la qualité du modèle (R2 ajusté, RMSE sur les résidus).
Étape 3 : Interpolation spatiale par régression linéaire
- Interpolation des cumuls de pluies annuels à l’échelle de la Bourgogne
- Découpage pour le BV de la Sorme et analyse des résultats
- Import des cartes des cumuls moyen des pluies annuelles dans QGIS;
Étape 4 : Interpolation spatiale basée par régression-krigeage
Nous reviendrons au cours du TP sur les différentes étapes.
Éléments pour l’évaluation
- Les documents ainsi que le script du TP4 sont à récupérer (ici)
Analyse spatiale de données géographiques : Pollution au phosphore dans un bassin versant
Objectifs pédagogiques :
- Savoir analyser des Données spatiales avec QGIS;
- Construire une stratégie (i.e. démarche méthodologique) d’analyse spatiale;
- Mettre en œuvre cette stratégie avec QGIS pour cartographier un risque de pollution diffuse d’origine agricole à l’échelle d’un bassin versant;
- Acquérir les bases de la géostatistique pour évaluer la cohérence spatiale de données;
- Développer un regard critique sur la qualité des données spatialisées, leurs intérêts et leurs limites, en particulier dans le cadre d’analyses environnementales;
- Exploiter la complémentarité QGIS/R;
La présentation de l’applicatif SIG, le support du TP et les données sont à récupérer ici
Séance 1
- Introduction à la problématique de pollution diffuse d’origine agricole sur le Bassin Versant étudié;
- Travail collégial sur le modèle de risque de fuite en phosphore établit par le consortium qui a traité le cas;
- Classification des niveaux de risque;
- Construction collégiale de la stratégie pour produire une cartographie du risque;
- Mise en oeuvre de la démarche d’analyse spatiale pour l’identification des niveaux de risque;
Séance 2
- Poursuite de la mise en oeuvre
- Traitement des données pour identifier les niveaux de risque;
- Finalisation des traitements;
- Production des résultats et de la carte du risque;
Nous reviendrons au cours du TP sur les différentes étapes.
Objectifs de la séance :
- Utiliser le logiciel R pour lire et traiter des tableaux de données
- Créer et manipuler des séries temporelles. Mobilisation de ’packages adaptés’
- Appliquer des méthodes et des outils statistiques permettant la détection de ruptures et de tendance dans des séries climatiques
- Produire des résultats sur des séries climatiques observées enregistrées par des stations Météo-France sur le territoire métropolitain
Pour rappel :
- avec R les # permettent de mettre des commentaires dans le code
- Pour l'assignement dans un objet on peut utiliser les signes <- ou =
- Parmis les fonctions très utiles pour explorer les données :class, str, dim, head, tail
Les librairies à installer pour le TP sont :
Le script et la documentation sont à récupérer ici : ressources
Le données climatologiques quotidiennes de base que nous utiliserons seront à récupérer sur le site de Météo-France. La période sur laquelle vous travaillerez est 1950-2022 pour un département métropolitain. Un jeu test est néanmoins disponible ici data
Nous reviendrons au cours de la séance pas à pas sur les différentes étapes.
Bienvenue sur mes pages
Bonjour et bienvenue sur mes pages. Ces pages sont destinées à présenter et appuyer mes activités d’enseignement et de recherche. Pour la partie enseignement elles s’adressent en premier lieu aux élèves-ingénieurs de l’institut Agro Dijon et aux étudiants du Master SEME de l’université de Bourgogne. Elles me permettent de mettre à disposition les supports (scripts, données, notebooks, diaporamas etc.) et diverses informations utiles en amont soit de mes interventions ou de celles des intervenants extérieurs.
---
Pour les élèves-ingénieurs de la dominantes R2D2C -> cf. page 'Remise à niveau R'
Pour les élèves du Master 2 SEME -> cf. page 'Analyse des séries temporelles avec R'
---